如何逆向
本文翻译自《Reverse Engineering a DS Game》。
汇编语言(简称为汇编或
汇编入门
本教程旨在提供汇编语言的简要介绍,帮助你入门。为了简洁起见,我会跳过一些细节。如果你对更全面的
NDS 汇编参考感兴趣,可以查看 Tonc 的 ARM 汇编快速指南。
不同的
除了
ARM,NDS 的 CPU 还支持另一种指令集:THUMB。与 ARM 相比,THUMB 的指令更简单,但需要更多的指令来实现与 ARM 相同的功能。许多 DS 游戏(如《空之探险队》)主要使用 ARM 代码,虽然一些 DS 游戏大量使用 THUMB 指令集。尽管本教程不涉及 THUMB 指令集,但一旦你掌握了 ARM 指令集,学习 THUMB 会相对容易。
以下是一个简单的汇编赋值指令。
1 | mov r0, #0x0 |
这条语句将数字r0,r0
寄存器
寄存器是
CPUrX,其中r0r15,每个寄存器可以存储多达
r15
其他一些寄存器也有特殊名称和用途,我们稍后会讨论这些。
内存
寄存器容量有限,因此如果程序需要存储的数据超过寄存器的容量,数据会存储到主内存,也被称为
ROM
用于加载游戏的
在讨论
直接访问
overlay
overlay
NDS
《空之探险队》有
在游戏中访问overlay_0029.bin
例外情况是arm9.binarm7.bin。它们包含游戏的核心系统,例如加载arm9.binarm7.binarm7.bin。
在之前的
Ghidra 设置过程中,你将 arm9.bin的基址设置为 0x2000000,并将 overlay 文件设置为它们各自的地址。这与 DS 在内存中加载 ROM 文件的位置相匹配,将这些地址提供给 Ghidra 有助于它更好地分析代码。
每个可以加载的arm9.binarm9.binarm9.bin
查找
每个y9.bin。你可以使用十六进制编辑器打开这个文件,如
在y9.bin
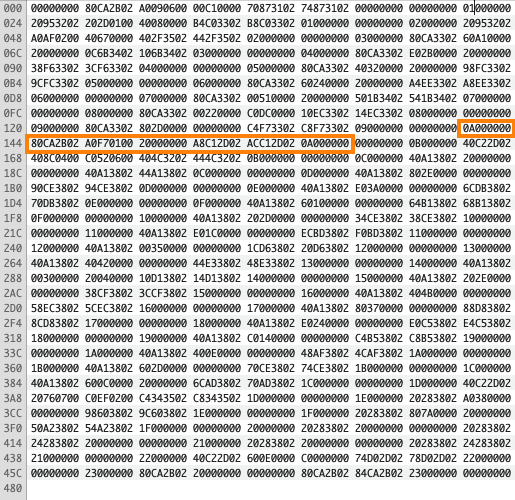
一旦知道了
大多数游戏都有一个内存区域列出当前加载的
指令
指令是用于操作寄存器或内存中的数据的。CPU
每条指令都是
赋值
下面是之前展示的赋值指令:
1 | mov r0, #0x0 |
该指令有三个部分:
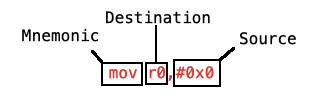
- 助记符:要执行的操作的简写名称。
mov指令将一个值赋给寄存器。 - 目标:要设置值的寄存器。在此指令中,将设置
r0的值。 - 源:要存储在目标寄存器的值的来源。在这种情况下,值是常量
0;在汇编术语中,被称为立即数(immediate number,意为该数不表示任何内存地址而直接表示一个值,所以为什么不翻译成直接数呢——译注)。
将这三部分结合起来,这条指令将r0r0
来源也可以是另一个寄存器。以下指令将r1r0
1 | mov r0, r1 |
算术
我们来看另一种类型的指令。下面的指令是一条加法操作。
这条指令将r1r0
1 | add r0, r1, #0x1 |
r0r1#0x1。可以将一个寄存器与一个立即数相加,或者两个寄存器相加。如果指令使用立即数,立即数必须始终位于最后;这个限制与指令在
如果你想将立即数加到寄存器值上,并将新值存回同一个寄存器,你可以使用以下简写。
1 | add r0, #0x1 |
这条指令把r0r0r0
其他可用的数学运算符包括减法、乘法、取负、按位与
你可能注意到没有除法指令。与上面列出的操作相比,任意数的除法要复杂得多,因此它实现为一个函数,而不是一条指令。这意味着除法比其他数学操作要慢得多。注意,右移操作符可以通过
2 的幂将数字除以某些值,从而在一条指令中实现某些除法。
如果两个来源都是寄存器,ARM
1 | add r0, r1, r2, lsl #0x2 |
上面的指令先将r2r0 = r1 + r2 * 4。
加载
寄存器只能存储少量的值,因此程序的大部分数据存储于内存。前文提到,内存(也可称之为主内存或
以下是一条把值存储到内存的指令。
1 | str r0, [r1, #0x4] |
- 助记符
“str” 表示 “存储寄存器(store register)”。 r0是源寄存器,包含要存储到主内存中的值。 - 中括号里的
r1(寄存器)和#0x4(可以是立即数或寄存器)相加,结果作为存储值的内存地址。立即数可以为0,表示将值直接存储到 r1中的地址。
例如,如果r0r1
替代指令strhstrb
从内存加载数据的格式与存储类似,只不过数据流的方向相反。
1 | ldr r0, [r1, #0x4] |
“ldr”r1r0strldrh)和单字节(ldrb)的指令。
除了从寄存器地址加载数据,ldrDAT_<address>,其中<address>
1 | ldr r0,[DAT_02090fe8] |
这将把值r0
为了方便,Ghidra
使用 DAT_<address>标记数据值。在底层, ldr指令包含从指令在 ROM 中的地址到数据值地址的 13 位有符号偏移量。
分支
到目前为止,所有指令都是按顺序逐行执行的。程序执行一条指令,程序计数器加
- 执行地址为
0x2000000 的指令。 - 将程序计数器增加到
0x2000004。 - 执行地址为
0x2000004 的指令。 - 将程序计数器增加到
0x2000008。 - 执行地址为
0x2000008 的指令。
如此继续。
分支指令(也被称为条件语句或跳转)可以将程序计数器设置为特定的值,从而使程序执行跳转到指定的指令。
以下是一条无条件分支指令。
1 | b LAB_02090fdc |
LAB_02090fdc
以上例为例,如果分支指令位于地址
- 执行地址为
0x2000000 的指令。 - 将程序计数器增加到
0x2000004。 - 执行地址为
0x2000004 的 b LAB_02090fdc指令。 - 分支指令将程序计数器设置为
0x2090FDC。 - 执行地址为
0x2090FDC 的指令。 - 将程序计数器增加到
0x2090FE0。 - 执行地址为
0x2090FE0 的指令。
如此继续。分支之后,程序计数器继续按顺序增加并执行指令。
与数据值类似,分支指令在底层包含从指令地址到跳转目标的偏移量。对于分支指令,偏移量长度为
26 位。
除了b
bl:用于函数调用的分支指令,稍后将讨论。bx:把寄存器的值作为地址跳转。
条件分支
可以编写仅在满足某个条件时才执行的分支指令。如果条件不满足,条件分支指令将被跳过,程序计数器递增并继续执行下一条指令。
条件分支由两条指令组成。以下是一个示例。
1 | cmp r0, #0x1 |
在这一组指令中,如果r0LAB_02090f14。如果
cmp指令比较两个值来设置条件分支。第一个值始终是寄存器,第二个值可以是立即数也可以是另一个寄存器。 - 所有条件分支指令都以字母’b’
开头,并以一个助记符扩展(也即条件码)结尾,指定需要满足的条件类型。在本例中,扩展 eq表示如果比较值相等,则执行分支。
条件分支指令支持所有基本的比较操作符:
- 等于:
beq - 不等于:
bne - 大于:
bgt,bhi - 大于等于:
bge,bcs - 小于:
blt,bcc - 小于等于:
ble,bls
等于和不等于各有一条指令,而其他比较操作符有不同的版本,以支持无符号整数、有符号整数和浮点数的比较。每个比较操作符的条件码的完整列表可以在
ARM
1 | cmp r0, #0x1 |
与普通条件分支一样,cmpcmpbr0r0r1。所有指令都允许附加条件码。
像if/else if/elsewhile/do while/for。这些结构通常在编译为汇编代码时转换为条件分支语句。
在
CPU 内部, cmp指令设置了四个位的条件标志,分别为 C、N、V 和 Z。每条条件分支指令都检查特定的条件标志以决定是否执行分支。例如, beq指令会在 Z=1 时执行分支。你很可能不需要直接与这些条件标志交互,了解条件码就足够了。
函数
在概念层面,汇编中的函数与高级语言中的函数类似。一个函数可以被调用,然后该函数运行,最后返回到调用该函数的代码。函数还可以有参数和返回值。让我们更深入地了解汇编中的函数是如何工作的。
一个函数可以通过如下方式调用:
1 | bl FUN_022de288 |
blFUN_022de288lr),对于lrr14。函数结束时将检索链接寄存器的值,以便将程序返回到调用函数的位置。
下面是一个简单的函数:
1 | FUN_022de288 |
默认情况下,GhidraFUN_022de288。
大多数函数包含三部分:序幕、主体和尾声。序幕和尾声分别包括函数执行的标准设置和清理步骤,而主体是函数执行的主要逻辑。在上述函数中:
- 该函数简单到没有序幕。
- 主体包含指令
ldr r0, [r0, #0x0]。 - 尾声包含指令
bx lr。该指令将pc设置为 lr中的值,于是程序将返回到调用该函数的地方。
一旦函数从尾声返回到调用函数,pc
函数参数
要将参数传递给函数,需要在调用函数之前将参数存储在寄存器中。r0-r3
在下面的代码中,给r0FUN_022de288。
1 | ... |
一旦进入函数,函数就可以使用来自r0
1 | FUN_022de288 |
返回值
如果函数需要返回一个值,返回值将在函数返回之前存储在r0r0
在函数FUN_022de288r0,然后用bx
1 | FUN_022de288 |
调用者可以调用该函数,然后从r0
1 | bl FUN_022de288 |
调用栈
当调用一个函数时,调用者可能已经在使用寄存器来存储值。寄存器数量有限,函数也可能需要这些寄存器来完成其工作。在函数使用寄存器之前,它应该保存它计划使用的寄存器的现有值。当函数完成时,它应该将保存的值恢复到寄存器中,这样调用者在恢复执行时不会丢失当前状态。
寄存器r0-r3r12r4-r11lr(译注:也就是r14)。
由于一个函数可以调用另一个函数,而该函数又可以调用另一个函数,如此反复,所以每个函数都必须在适当的时间存储和恢复寄存器的值。这是通过使用被称为调用栈(call stack)的内存位置来完成的。
调用栈,通常简称为栈,是内存中的一个特殊位置,用于在函数调用时保存寄存器的值。如果寄存器中没有足够的空间,它还用于存储局部变量。顾名思义,它是一个先进后出的(LIFO)数据结构。栈顶的地址由r13sp)。
函数序幕的主要目的之一就是将寄存器的值保存到栈中。寄存器的值通过stmdb(store multiple, decrement before)指令压到栈顶(即sppush
以下是一个序幕示例,保存了寄存器的值。
1 | stmdb sp!, {r4 lr} |
该序幕取自一个使用r4bllrr4lr
在函数尾声中,通过使用ldmia(load multiple, increment after)指令,也可记作pop,将保存的寄存器值恢复到原始值。这是上面序幕对应的尾声。
1 | ldmia sp!, {r4 pc} |
ldmialdmiasp,使栈顶移动到已经出栈的项之后。在上述示例中,r4pclr
除了保存和恢复寄存器值之外,栈还有几个其他用途。
栈中的局部变量
如果一个函数有很多局部变量,或者像结构体、数组这样的大型局部变量,可能会耗尽寄存器来存储所有变量。如果发生这种情况,溢出的值都将存储在栈中。如下代码展示了这种情况。
1 | sub sp, sp, #0x1c |
在函数序幕中,栈指针被减去0x1c,为局部变量腾出空间。函数通过使用相对于spsp
Ghidralocal_24,而不是显示相对于sp
栈中的函数参数
有四个寄存器可用于函数传参。如果函数需要超过四个参数,额外的参数将被存储在栈中进行传递。栈也用于传递较大的数据类型,如结构体和数组。
下面是一个向函数传递五个参数的例子。
1 | ; Prologue |
与栈中的局部变量一样,序幕通过从spFUN_02332bacr0-r3str r2, [sp, #0x0]sp
在FUN_02332bacsp
1 | FUN_02332bac |
以上关于传递参数、返回值、保存寄存器和分配局部变量的模式都是
结构体
分析汇编代码,可以判断出像
在int
1 | struct Position |
这个结构体的大小是xxy
典型的汇编代码会维护一个指向结构体开始位置的指针,并使用偏移量来访问结构体的每个字段。以下代码是将值存储到结构体中的一个示例。
1 | ldr r0, [DAT_02073b70] ; Load the address of a Position. |
在逆向工程社区中,常见的情况是有一个结构体字段,但是用途尚不明确。社区通常会根据未知的字段的偏移量命名。例如,如果上面的结构体还没有被识别为存储位置信息的结构体,它可能会使用类似如下的命名:
1 | struct unkStruct |
复制结构体数据
对结构体的一种常见操作是将值从一个结构体复制到另一个结构体。有一些特殊的指令可以批量加载和存储值:ldmiastmia。我们已经在入栈和出栈时见过类似的指令,现在让我们更详细地了解它们。
ldmia
1 | ldmia r1!, {r3 r4 r5} |
r1r1r1r1r3、r4r5。
例如,如果r1ldmia
- 将地址
0x2000000 处的值加载到 r3。 - 将
r1递增到 0x2000004。 - 将地址
0x2000004 处的值加载到 r4。 - 将
r1递增到 0x2000008。 - 将地址
0x2000008 处的值加载到 r5。 - 将
r1递增到 0x200000C。
也可以传递一组寄存器范围来进行加载,而不是列出每个单独的寄存器。
指令中的
“!” 表示 “写回模式”,这意味着源寄存器会被指令递增。在某些指令集中,可以省略 “!” 以保持源寄存器不变。
stmialdmialdmiastmia
1 | stmia r2!, {r3 r4 r5} |
如果r2stmia
- 将
r3中的值存储到地址 0x2000000。 - 将
r2递增到 0x2000004。 - 将
r4中的值存储到地址 0x2000004。 - 将
r2递增到 0x2000008。 - 将
r5中的值存储到地址 0x2000008。 - 将
r2递增到 0x200000C。
在ldmiastmialdmia/stmia
1 | ldmia r1!, {r3 r4 r5} |
这些指令将从r1r2
使用ldmiastmia
数组
在汇编中,有几种方式可以实现数组的访问。
在很多方面,数组与结构体类似。如果访问一个硬编码的数组索引(即循环外的访问),会使用偏移量来访问数据,类似于结构体。复制数组数据也类似于复制结构体,通常使用相同的ldmia/stmia
如果在循环中访问数组,仍然可以使用偏移量,只不过每个数组元素的偏移量必须递增或重新计算。以下示例遍历了一个包含
1 | ldr r2, [DAT_02073b70] ; Load pointer to start of array. |
另一种方式是从数组指针初始化当前数组元素的指针并递增。
1 | ldr r2, [DAT_02073b70] ; Load pointer to start of array. |
Switch
在汇编中,switchbpcb
例如,让我们看一个简单的
1 | int type; |
上面的
1 | ; Logic to assign r0 (type variable). |
有些
汇编入门总结
读到这里,你现在已经具备了阅读
下一步是探索一些能帮助逆向工程